Take Your Learning to the Next Level! See More Content Like This On The New Version Of Perxeive.
Get Early Access And Exclusive Updates: Join the Waitlist Now!
Take Your Learning to the Next Level! See More Content Like This On The New Version Of Perxeive.
Get Early Access And Exclusive Updates: Join the Waitlist Now!

The release of ChatGPT by OpenAI in November 2022 generated a huge amount of interest in Large Language Models (LLM's) which had garnered little attention previously. In particular, businesses around the world have been scrambling to articulate a strategy to use LLM technology to either drive efficiencies or generate incremental revenue. The lack of knowledge within these organisations, especially within the senior ranks is hampering progress.
Generative AI has exploded in popularity since OpenAI released ChatGPT as the chat interface made the technology more accessible to non-technical users. Since then a number of alternative GPT based technologies have released including Microsoft Copilot (originally Bing AI), Anthropic's Claude, Google Bard and before those both Character AI and Perlexity AI were released. The technology is becoming more broad based, capable and accessible to both consumers and businesses.
One of the primary risks associated with the use of third party LLM's is the potential for leakage of sensitive or proprietary data from businesses. One way to benefit from LLM's whilst eliminating the risk of data leakage is to use techniques such as Retrieval-Augmented Generation (RAG) in combination with running an open source LLM such as Meta's LLaMA locally.
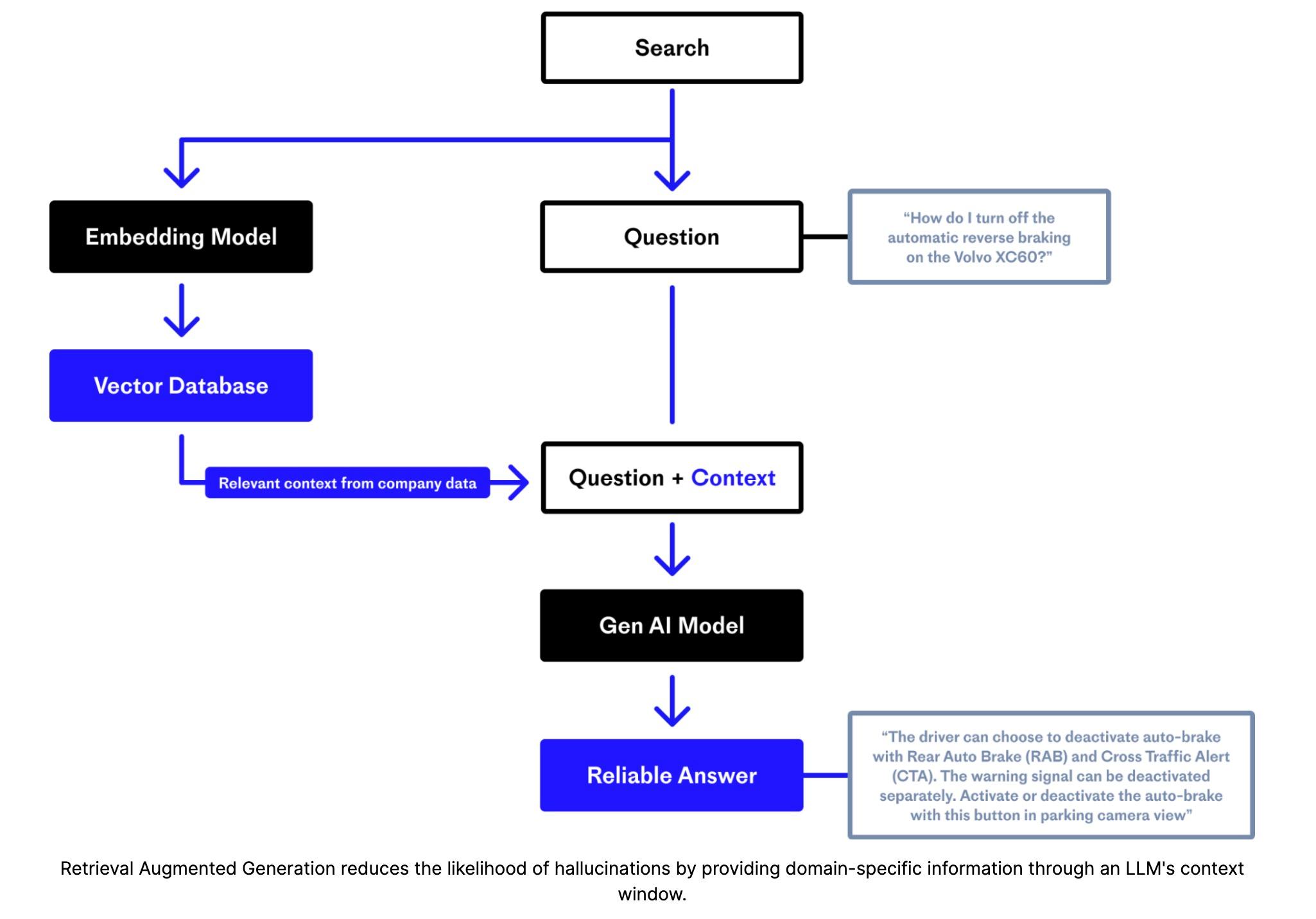
Retrieval-augmented generation is a technique that combines LLMs with an external knowledge source, such as a database or a collection of documents, to generate more accurate and informative responses. Businesses have vast amounts of data that is useful on a day-to-day basis but which is often difficult to access and often sits in silos that have gatekeepers acting as bottlenecks. Making this data more generally available and via a medium that has no technical barriers to access has the potential to unleash huge productivity gains and power new business opportunities.
As both an early adopter of LLM technology via the Perxeive app I released to the Apple App Store in November 2021, and as someone who has operated in senior management roles in large businesses I believe RAG techniques offer the optimal initial LLM implementation strategy for most businesses. Deploying RAG solutions offers business the best way to both demonstrate progress and to minimise the risks associated with a revolutionary new technology.
The RAG approach can be used to deploy real-world applications of LLMs in the following ways:
There are many potential applications both for internal use and also for client facing. For those businesses wishing to make a start in using LLM's in their businesses an internal deployment of a RAG application is a low risk strategy. This could be as simple as deploying a chat application that enables employees to query internal policies and procedures. A good example for businesses operating in highly regulated sectors such as financial services providing tools that enable regulations to be queried for a specific context and the relevant sections of regulations to be referenced and summarised could be hugely valuable.
External customer applications could include enabling customers to self serve learning how to use a product via a RAG enabled chat bot.
The architecture of a RAG application consists of two main components: a retriever and a generator. The retriever is responsible for searching a large corpus of documents to find relevant information related to the user's query, while the generator uses this information to generate a response.
During inference, the retriever first identifies a set of potentially relevant documents based on the user's input. It then extracts salient snippets from these documents and passes them to the generator, which uses them as context to generate a response. On a practical basis, this typically is implemented as a query to a vector store in which a business has represented its text data as a set of semantically optimised embeddings.
Pinecone is an example of a fully managed vector database that is well suited to RAG applications. Having implemented RAG using Pinecone for my own educational purposes I found Pinecone very straightforward to set up and use. Vector stores and embeddings are covered in a later section below.
The generator is typically a pre-trained transformer model that has been fine-tuned for a specific task, such as question answering or dialogue generation. Proprietary LLM's such as OpenAI's various GPT's and open source models such as Meta's LLaMA are examples of potential generators.
The following figure is taken from the Pinecone blog on RAG and provides an example of a RAG architecture:
The RAG architecture has several advantages over traditional generative models. By incorporating retrieved information into the generation process, it can provide more accurate and relevant responses to user queries. Additionally, because the retriever only needs to search a fixed corpus of documents, it can be more efficient than generating responses from scratch using a large language model.
One potential limitation of the RAG architecture is that it requires access to a large and diverse corpus of documents to be effective. If the corpus is too small or not representative of the domain being queried, the retriever may not be able to find relevant information, which could negatively impact the quality of the generated response.
Vector stores and embeddings are important concepts in retrieval-augmented generation.
A vector store is a data structure that is used to efficiently retrieve vectors (i.e., numerical representations of data) based on their similarity to a query vector. In the context of retrieval-augmented generation, a vector store might be used to index and retrieve embeddings of text documents, which can then be used to generate responses to user queries.
Embeddings are compact vector representations of data that capture its semantic meaning or other relevant properties. In the case of text data, embeddings can be generated using techniques such as word2vec, GloVe, or BERT. These embeddings capture the meanings of words and phrases in a way that allows them to be compared and manipulated mathematically, which is essential in RAG applications.
There are a number of ways in which the text can be broken down into semantically relevant chunks to be embedded into the vector store. We cover text splitting and chunking in more detail in a later section.
In retrieval-augmented generation, embeddings are used to represent the meaning or context of user queries and text documents. By comparing the embeddings of a query and a set of relevant documents, the model can identify the most relevant documents to use in generating a response. The vector store is then used to efficiently retrieve these documents based on their similarity to the query embedding.
Vector stores and embeddings are important tools for retrieval-augmented generation because they allow models to efficiently compare and retrieve relevant information based on its semantic meaning or other properties. This can lead to more accurate and contextually relevant responses, which is particularly important in applications such as chatbots, virtual assistants, and other natural language processing tasks.
Text splitting and chunking are techniques used to divide large text documents into smaller pieces or chunks, which can then be processed and analyzed more efficiently. These techniques are often used in natural language processing (NLP) and machine learning applications that involve working with text data, such as text classification, sentiment analysis, and information retrieval.
Text splitting and chunking are essential in the development and deployment of RAG applications as they enable large text documents to be represented in vector stores.
There are several methods for splitting and chunking text, including:
When it comes to vector stores and embeddings, text splitting and chunking techniques are important for several reasons:
Text splitting and chunking techniques are important tools for working with text data in natural language processing and machine learning applications. By dividing text into smaller chunks, it is possible to process and analyze text more efficiently, while also improving the quality of embeddings and handling long documents more effectively.
Retrieval-augmented generation applications represent a low risk opportunity for businesses to demonstrate progress in their adoption of LLM technology. Internally deployed RAG applications enable a business to learn how to develop and deploy LLM technology whilst maintaining data security. There are potential quick wins to improve productivity by making internal data available to employees via a medium that is intuitive and which has minimal barriers to adoption.
Successful internal deployments then set a business up for success when deploying RAG applications to their customers.
Deploying RAG solutions offers business the best way to both demonstrate progress and to minimise the risks associated with a revolutionary new technology.